
What is Hadoop?
Hadoop is an open-source framework planned to make interact with big data. The term Big Data is given to the datasets which can not be processed with the help of the traditional RDBMS approach. Hadoop enables the processing of huge datasets which are occupied in the form of clusters.
Hadoop Ecosystem:
It is a platform that provides a variety of services to solve big data problems. Below are the components that form the Hadoop ecosystem altogether:
HDFS: Hadoop Distributed File System
YARN: Yet Another Resource Negotiator
MapReduce: Programming based Data Processing
Spark: In-Memory data processing
PIG, HIVE: Query-based processing of data services
HBase: NoSQL Database
Mahout, Spark MLLib: Machine Learning Algorithm Libraries
Solar, Lucene: Searching and Indexing
Zookeeper: Managing cluster
Oozie: Job Scheduling
1. HDFS:
Hadoop Distributed File System is the main component of the Hadoop ecosystem. It is possible for HDFS to store huge amounts of different types of data sets i.e., structured, unstructured, and semi-structured data.
HDFS consists of two core components i.e., NameNode and DataNode
NameNode is the primary node of the HDFS cluster that contains the metadata. It doesn’t store the data but it stores the information about the data.
DataNode is the one that stores the data and requires more storage resources. These DataNodes are commodity hardware in the distributed environment.
2. YARN:
Yet Another Resource Negotiator helps to allocate resources and schedule tasks.
It has two major components:
- Resource Manager
- Node Manager
(I) Resource Manager is the master node in the data processing, it processes the request and then passes the blocks of requests to its corresponding node manager accordingly.
(II) Node Manager:
It is a service that runs in each DataNode and is responsible for executing the tasks on every single Data Node. Node Manager knows everything about its machine, whether it is about RAM, Cores, Storage, Services, etc., and later acknowledges on Resource Manager.
3. MapReduce:
It is a framework that helps to provide the processing logic and write the application to solve the large data sets using distributed and parallel algorithms. It basically divides a single task into multiple tasks and processes them on different machines.
MapReduce has two functions i.e., Map function and Reduce function.
Map()- It filters, groups, and sorts the data, the input data is divided into multiple splits. Each map task works on a split of data in parallel and outputs as key-value pair.
Example-
(Key, Value)
(apple, 1)
(apple, 1)
(ball, 1)
(ball, 1)
(apple, 1) After shuffle, sort, group by it becomes
apple [1,1,1]
ball [1,1]Reduce()- It summarizes and aggregates the output produced by the map function as a key-value pair (k,v) which acts as an input for reduce function.
Example- Below is the final output.
(apple, 3)
(ball, 2)
4. Apache PIG:
Apache Pig was developed by Yahoo in the year 2006 to execute the MapReduce job. It is a high-level abstraction over MapReduce for analyzing larger data sets.
It has two components: Pig Latin and Pig Engine:
Pig Latin Apache Pig works on a query-based language similar to SQL.
Pig Engine is the execution engine on which Pig Latin runs. Internally, the code written in Pig is converted to MapReduce functions.
5. Apache Hive:
Apache Hive was developed by Meta (Formerly Known as Facebook). It provides the functionality of writing, reading large data sets. It runs SQL queries and is also known as HQL (Hive Query Language) which internally gets converted to MapReduce jobs. SQL data types are supported by Hive which makes query processing easier.
It is highly scalable, and it can serve both real-time processing and batch processing.
It has two components: Hive Command-Line and JDBC/ODBC driver
Hive Command Line is used to execute the HQL commands. Whereas, JDBC/ODBC driver is used to establish the storage connection and permission.
6. Mahout:
It is an environment for creating Machine Learning Applications. It provides a lot of functionalities such as collaborative filtering, clustering, and classification. These are the concepts of Machine learning.
7. Apache Spark:
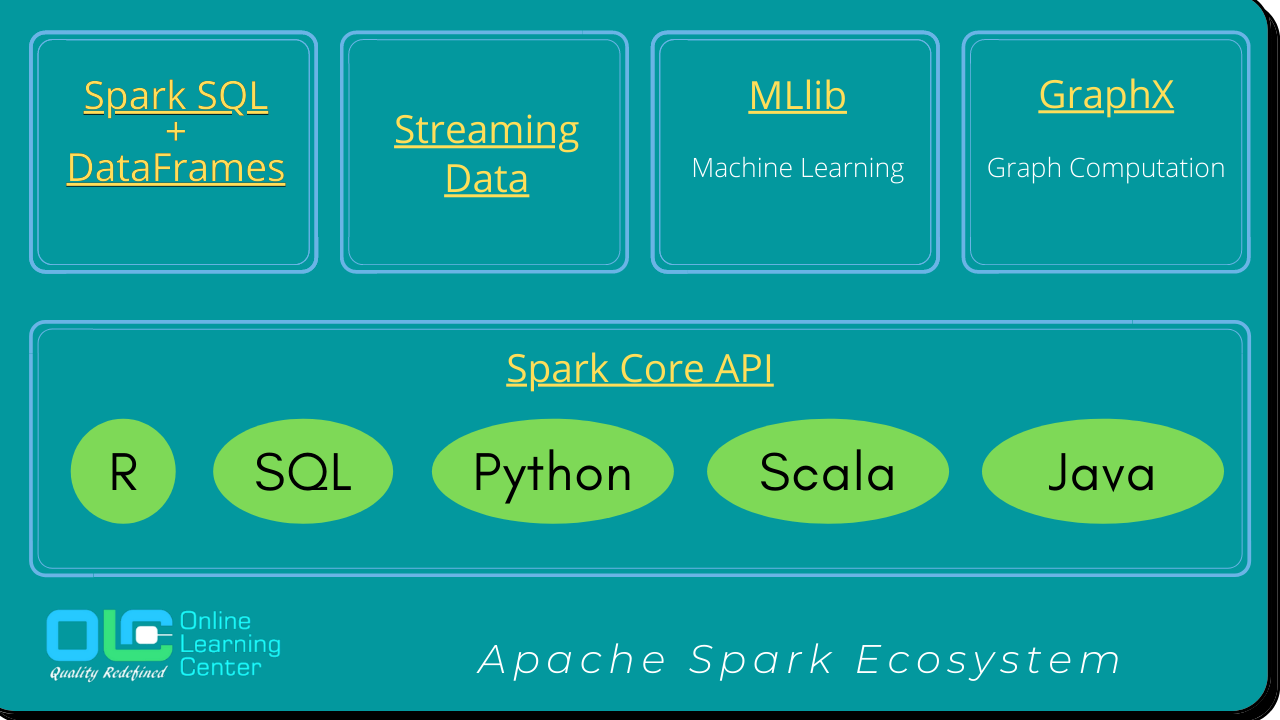
Spark is basically a big data processing framework that helps to process the data on a very large scale. Developed at 𝗨𝗖 𝗕𝗲𝗿𝗸𝗲𝗹𝗲𝘆’𝘀 𝗔𝗠𝗣𝗟𝗮𝗯 2009 by 𝗠𝗮𝘁𝗲𝗶 𝗭𝗮𝗵𝗮𝗿𝗶𝗮 and later in the year 2013, it was donated to 𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗼𝗳𝘁𝘄𝗮𝗿𝗲 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 (𝗔𝗦𝗙). The main feature of Spark is, it is an In-Memory cluster computing that increases the processing speed of an application. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. Spark not only supports MapReduce. It also supports SQL queries, Streaming data, Machine learning (ML), Graph computation.
8. Apache HBase:
It is a NoSQL Database, designed to run on top of HDFS, and is capable of handling any type of data. It basically retrieves the occurrences of a small amount of data in a large database.
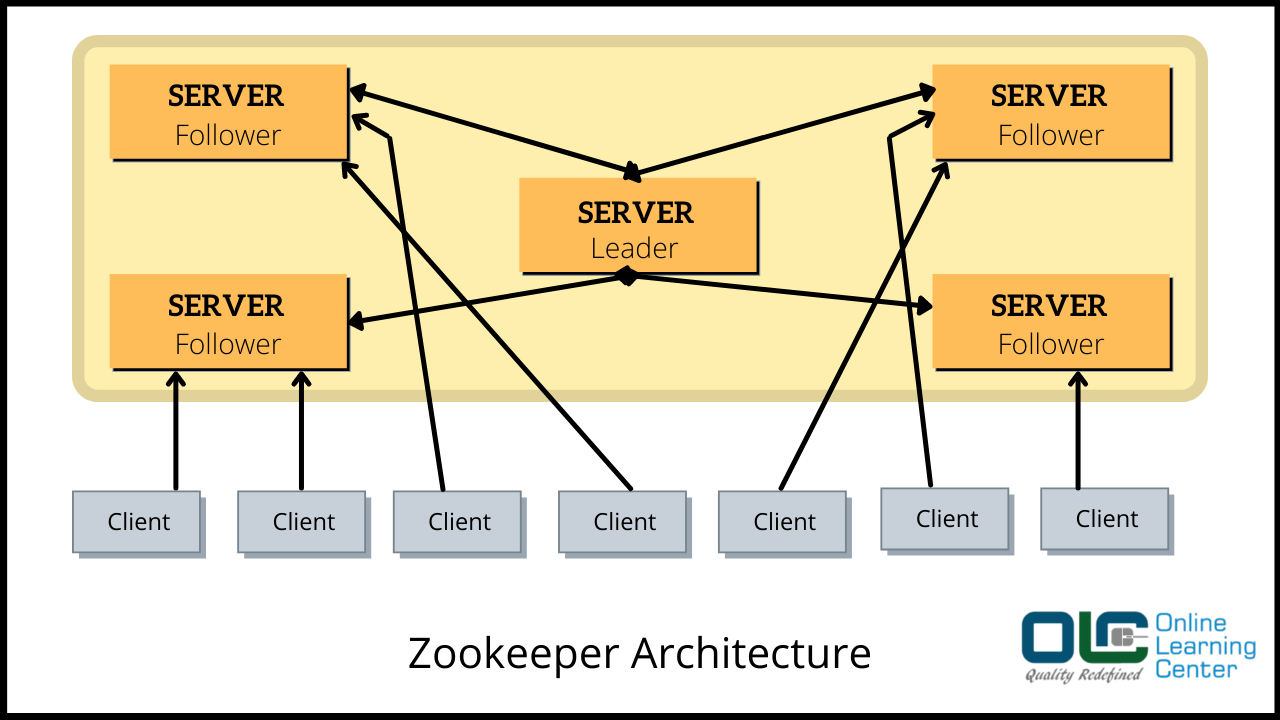
9. Zookeeper:
Zookeeper helps you to maintain configuration information, naming, group services for distributed applications. It allows you to select a node as a leader for better coordination. It follows the client-server model.
10. Oozie:
It acts as a scheduler. it schedules the jobs and binds them together into a single unit. Jobs are of two types: Oozie Workflow and Oozie coordinator jobs. Oozie Workflow jobs are executed in a sequential manner. Whereas, Oozie coordinator jobs trigger when the data is available.
