
What is Hadoop?
Hadoop is a quite popular framework that has a big hand in solving big data problems. Hadoop is built for computing large data or a huge volume of data. Introduced by “Dough Cutting” along with “Mike Cafarella” (Co-Founder). This framework is written in the Java programming language.
Journey of Hadoop:
- Year 2002: they both started to work on the Apache Nutch
- Year 2003: they came across a paper that described the architecture of Google’s distributed file system, called GFS.
- Year 2004: Google published one more paper on the technique MapReduce, which was the solution for processing those large datasets.
- Year 2006: Doug Cutting joined Yahoo along with Nutch project formed a new project Hadoop.
- Year 2007: Yahoo successfully tested Hadoop on a 1000 node cluster and start using it.
- Year 2008: Yahoo released Hadoop as an open-source project to ASF (Apache Software Foundation).
- Year 2011: Apache Software Foundation released Apache Hadoop version 1.0.
Initially, Hadoop started with 2 components 𝗛𝗗𝗙𝗦 & 𝗠𝗮𝗽𝗥𝗲𝗱𝘂𝗰𝗲.
- 𝗛𝗗𝗙𝗦 is an ability to store the data or dataset in the node cluster which can be divided into pieces or blocks where each piece would be a maximum of 128 MB.
- 𝗠𝗮𝗽𝗥𝗲𝗱𝘂𝗰𝗲 is a framework that can help to process the data.
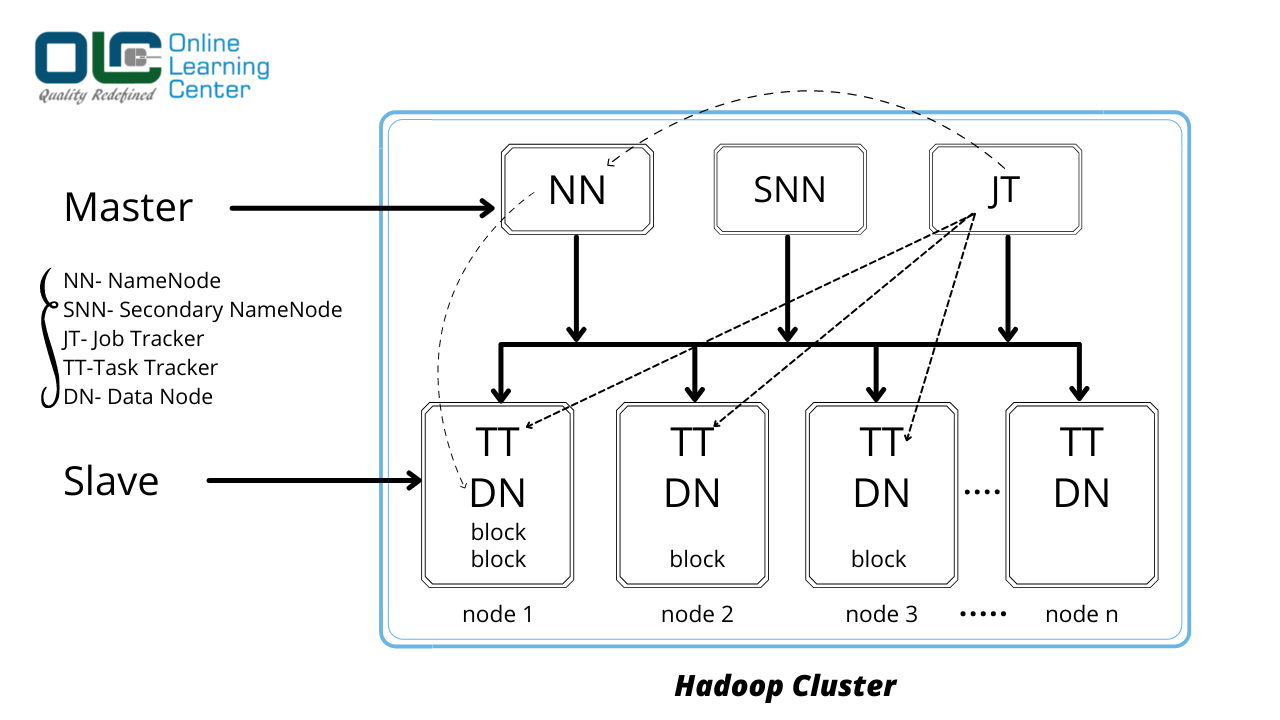
Hadoop 1 Architecture:
When we install Hadoop into any system, it comes with certain services or Daemons like: NameNode, Secondary NameNode, Job Tracker, Task Tracker, Data Node. These services are a part of Hadoop 1 Architecture. The default block size is 64 MB which can be configured.
It follows the Master-Slave structure in which we have one or more devices in the Master node where-in we have NameNode, Secondary NameNode, Job Tracker.
And we have ‘n’ number of nodes in a cluster where-in we have Task Tracker, Data Node in a Slave Machine.
Hadoop 1 Daemons Terminologies:
Daemons of Hadoop 1 Architecture are as follows:
- Secondary NameNode
- NameNode
- Job Tracker
- Task Tracker
- Data Node
NameNode:
NameNode is the masterpiece of an HDFS. It keeps the directory tree of all files in the File System, and tracks where across the cluster file is kept. It does not store the data of these files itself.
Secondary NameNode:
The NameNode stores the HDFS File System information in a file named FSIMAGE, Updates to the file system (add/remove blocks) are not updating the FSIMAGE file, but instead of Logging in to a file. When restarting, the NameNode reads the FSIMAGE and applies all the changes from the log file to bring the file system state up-to-date in memory. This process takes time.
Job Tracker:
The Primary function of Job Tracker is resource management (managing Task Tracker), tracking resource management (tracking its progress, Fault Tolerance, etc.)
Task Tracker:
The Task Tracker has a simple function of following the orders of Job Tracker and updating the Job Tracker with its progress status periodically.
DataNode:
The Data Node is actual where data resides. All Data Nodes sends a message to the NameNode every 3 seconds to say that they are alive. If the NameNode does not receive a message from a particular Data Node for 10 minutes, then it considers that Data Node to be dead or out of service and initiates replication of blocks that were hosted on that Data Node to be hosted on some other Data Node.
How Does Hadoop Maintains Duplicate Data?
It is possible that over the period of time where we have all the machines continuously up and running and performing a lot of processing things, then there could be a chance of machine failure due to many reasons.
We are not using a supercomputer for our Hadoop setup. That is why we need such a feature in HDFS that can make copies of that file blocks for backup purposes, this is known as fault tolerance.
Hadoop has the feature of replicating the data which means maintaining the duplicate copy in some other nodes.
So, by default, the replication factor is 3 which means 2 more copies would be replicated by Hadoop in some other machines also.
HDFS is maintained by 2 Daemons i.e., 𝐍𝐚𝐦𝐞𝐍𝐨𝐝𝐞 & 𝐃𝐚𝐭𝐚𝐍𝐨𝐝𝐞.
The NameNode contains all the details of HDFS like where the data is stored in which node or machine. How many copies are stored and locations, and so on.
Whereas, DataNode is a process that manages the data and, gets it stored.
This DataNode is always keep in touch with NameNode and pings about its liveliness. If NameNode stops getting pings from a DataNode, then NameNode understands that node is down for some reason.
Data Processing in Hadoop:
In Hadoop, in order to process the data, we will have to execute some programs or say it is a job. The job would be written in MapReduce, Hive queries, or whether it would be a Spark job or Scala-Spark job, etc.
Talking about MapReduce, it processes the data by dividing them into subtasks and executing them in parallel across multiple nodes in the cluster.
So, a MapReduce job that contains phases like- Mapper class, Reducer class, and Driver class. The input and output of the phases are the key-value pair.
The programmer specifies two functions, map function and reduce function:
𝗺𝗮𝗽 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻- the execution of business logic for processing the data done here
𝗿𝗲𝗱𝘂𝗰𝗲 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻- the programmer writes the logic for the intermediate output of the map function and generates the output and stored on HDFS.
This particular execution information would be given to the Job Tracker, it then takes the support of NameNode and enquires about the task and gathers all the information of the data that resides in different nodes.
NameNode & Secondary NameNode:
NameNode is a daemon of Hadoop Architecture where it plays the role of maintaining a Register or Metadata which contains all the details of files or blocks of files or replica files, that are stored on a Hadoop.
It is always advised not to store a lot of small files because it makes the register heavy and it goes with a lot of entries in NameNode. This Register is nothing but a file and this is of 2-types: 𝐅𝐒𝐈𝐌𝐀𝐆𝐄, 𝐚𝐧𝐝 𝐄𝐝𝐢𝐭𝐋𝐨𝐠:
These 𝐅𝐒𝐈𝐌𝐀𝐆𝐄 and 𝐄𝐝𝐢𝐭𝐋𝐨𝐠 are the files where the data would be stored in NameNode. All operations like- upload file, change permission, delete a file, and so on are stored in EditLog and it starts growing periodically.
𝐒𝐞𝐜𝐨𝐧𝐝𝐚𝐫𝐲 𝐍𝐚𝐦𝐞𝐍𝐨𝐝𝐞 keeps a copy of FSIMAGE. Periodically Secondary NameNode will get the copy of the FSIMAGE file and the Edit logfile from the NameNode and apply the log file to the FSIMAGE file. Secondary NameNode however doesn’t take over the functions of the NameNode if the NameNode encounters an issue.
Speculative Execution in Hadoop and How it works:
Since MapReduce job runs in parallel across multiple nodes in order to reduce the job execution time. When any job runs consistently let’s say hundreds or thousands of tasks then there could be the possibility of time-sensitive for slow-running tasks.
The task can be slow for many reasons like Network Issues, Hardware Mis-Configured, and so on. But it is very hard to detect the actual cause of running these slow tasks.
Now, what if a few data nodes in the Hadoop cluster are not executing the task faster than the other data nodes, then the framework understands that it is taking longer time than expected. The framework then detects and launches an equivalent task or duplicate task in some other node/machine. This process is known as 𝐒𝐩𝐞𝐜𝐮𝐥𝐚𝐭𝐢𝐯𝐞 𝐄𝐱𝐞𝐜𝐮𝐭𝐢𝐨𝐧 𝐈𝐧 𝐇𝐚𝐝𝐨𝐨𝐩.
When the task gets successfully completed, the duplicate tasks that are running would be killed.
In case, the original task gets completed before the speculative task (duplicate task) then the speculative job would be killed.
And, if the speculative task finishes the job before the original task, then the original task would be killed.
